С какой проблемы начинаем
Маркетплейсы растут, правил больше, отчётов — ещё больше. У каждого — свои форматы, задержки и ограничения. В итоге у команды десятки выгрузок, сотни таблиц, разные версии «правды» и вечная сводка «вручную». Руководитель не видит общую картину, категорийщик не успевает проверять остатки, маркетолог тратит бюджет на слепую рекламу. Деньги утекают — потихоньку, каждый день.
- Данные разрознены: Ozon, WB, ЯМ, 1C, MPStats.
- Excel тормозит и ломается на больших объёмах.
- Отчёты противоречат друг другу, спорим «кто прав».
- Нет истории и причин: «почему просел SKU?» — непонятно.
- Решения принимаем «на ощущениях», а не на данных.
- Неликвид копится, закупки делают «на всякий случай».
- Реклама без связи с остатками и ценой — деньги в пустоту.
- Команда занята сводками, а не управлением продажами.
Хранилище данных (DWH) решает это: все источники собираем, приводим к общей логике, обновляем автоматически. В любой момент понятно «что происходит» и «что делать».
Слева — разрозненные выгрузки и отчёты, справа — единая картина бизнеса.
Зачем это бизнесу
- Один источник правды по всем площадкам и SKU.
- Прозрачные отчёты: продажи, финансы, остатки, реклама, конкуренты.
- Прогноз спроса и рекомендации по цене и закупкам.
- Готовые выгрузки в Excel и визуализации в DataLens.
Кому это нужно
Подходит предпринимателям и командам, которые продают на нескольких площадках, хотят управлять ценами, остатками и рекламой на данных, а не в ручных таблицах.
- Продавцам на двух и более площадках (Ozon, Wildberries, Яндекс Маркет, Gold Apple).
- Командам, у которых данные разъехались между отделами и файлами.
- Компаниям, которые хотят прогнозировать спрос, управлять ценами и рекламой.
- Бизнесу, который вырос из Excel и хочет стабильный процесс.
Короткие схемы см. ниже в разделе «Примеры UML».
Архитектурные примеры (UML + иконки)
Краткие схемы для ориентирования. Убрали лишние автогенерированные блоки, оставили только полезные.
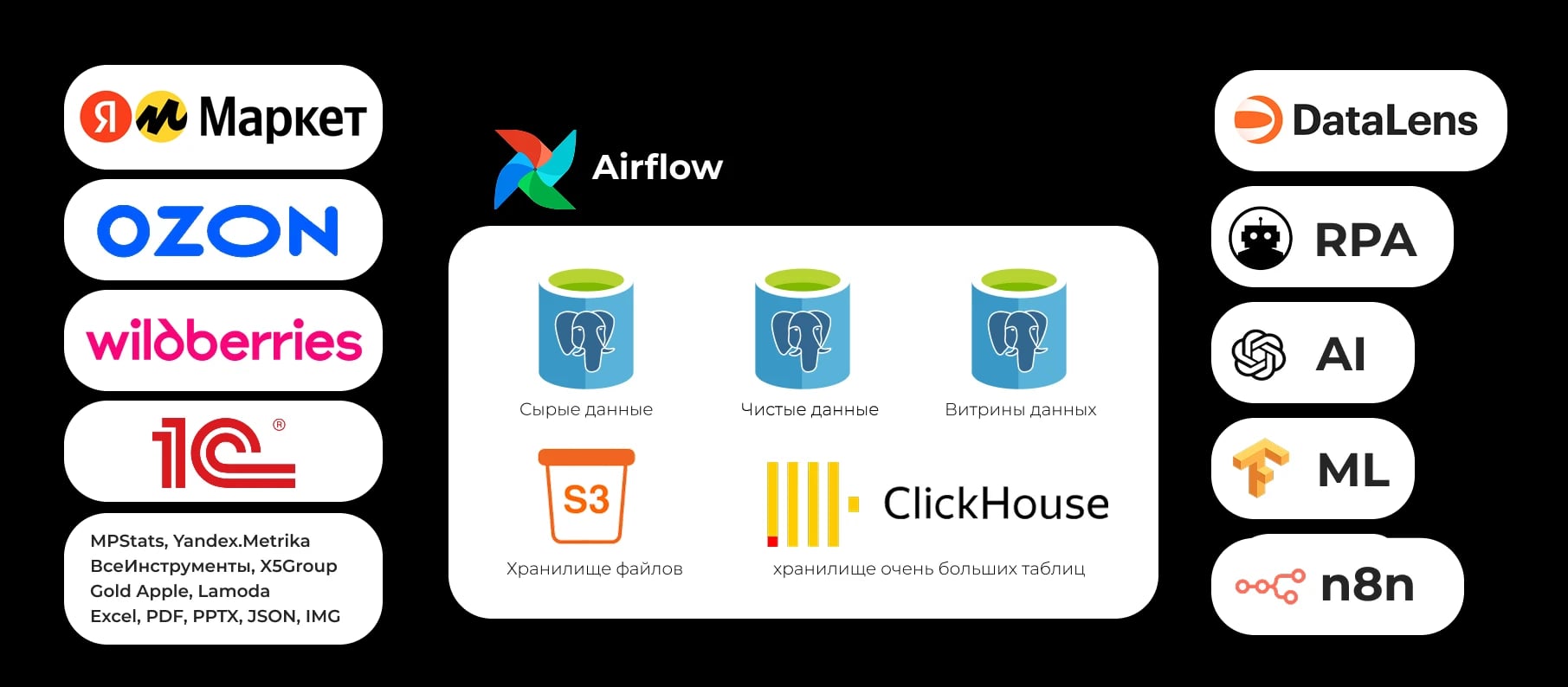
Поток данных: источники → витрины
Сырые данные сохраняем отдельно. Модель — слоистая. Витрины — под задачи пользователей.
Управление: код, сборка, оркестрация
Код → проверка → контейнеры → кластер → задачи по расписанию с отчётностью.
Что собираем
- Продажи по SKU, категориям, брендам.
- Остатки, логистика, скорость оборачиваемости.
- Цены, скидки, промо, конкуренты.
- Отзывы, рейтинг, тексты для анализа ИИ.
- Финансы: выплаты, комиссии, удержания.
- Реклама: ставки, показы, клики, конверсии.
- Справочники: карточки, SKU, номенклатура 1С.
- Внешние источники: MPStats и другие агрегаторы.
Источники: официальные API маркетплейсов, выгрузки, 1С, MPStats. Данные приводим к единому формату. Храним историю.
Почему важно хранить у себя
На сторонах маркетплейсов данные доступны ограниченное время и не покрывают все поля. Историю продаж, остатков, цен и отзывов площадки очищают или агрегируют. Поэтому мы сначала сохраняем «сырые» данные у вас (Staging), затем строим модель. Срок хранения и регламенты — на вашей стороне.
На схеме показаны сущности и связи, которые мы приводим к общей модели данных.
Архитектура решения
Строим слой за слоем. Обеспечиваем скорость, отказоустойчивость и прозрачность.
- Staging — сырые данные из источников. Не меняем.
- ODS — очищаем, валидируем, нормализуем. Готовим к моделированию.
- DWH — бизнес-модель: факты, измерения, историзация.
- Data Marts — витрины под отчёты: продажи, финансы, маркетинг.
graph TD A[Маркетплейсы/API/1C/MPStats] -->|Extract| B[Staging] B -->|Clean/Normalize| C[ODS] C -->|Model| D[DWH: Факты и Измерения] D -->|Aggregate| E[Витрины] E --> F[Отчёты / DataLens / Excel / BI] D --> G[ML/AI: прогноз, цены, реклама]
sequenceDiagram participant MP as Маркетплейсы participant ETL as Airflow ETL participant ST as Staging participant ODS as ODS participant DWH as DWH participant DM as Витрины MP->>ETL: API вызовы (продажи, остатки, цены) ETL->>ST: Сохраняем сырые данные ETL->>ODS: Чистим, нормализуем, валидируем ETL->>DWH: Загружаем факты и измерения (SCD) ETL->>DM: Агрегируем под отчёты DM->>Пользователи: Дашборды, Excel, выгрузки
Стек технологий (по категориям)
Языки
- Python — ETL, обработка данных, ML.
- TypeScript/JavaScript — веб‑интерфейсы, интеграции.
- Bash (Shell) — оркестрация окружений, скрипты.
Базы и хранилища
- ClickHouse — аналитика и быстрые агрегации.
- PostgreSQL — справочники, OLTP, интеграции.
- Redis — кеш/очереди.
- ChromaDB — эмбеддинги для LLM/VLM.
- MinIO (S3) — бэкапы, артефакты, выгрузки.
Оркестрация и инфраструктура
- Apache Airflow — DAG, ретраи, алерты.
- Kubernetes — масштабирование воркеров.
- Docker — изолированные окружения.
- GitLab/GitHub CI/CD — релизы и автодеплой.
Аналитика и отчёты
- Yandex DataLens — дашборды.
- Excel (XlsxWriter) — автогенерация отчётов.
- Next.js — веб‑приложения и админки.
ML/AI и LLM/VLM
- TensorFlow — прогноз спроса, рекомендации.
- OpenCV — проверка контента, CV‑задачи.
- LLM/VLM — анализ отзывов, поиск по описаниям.
Библиотеки
- pandas / numpy — подготовка данных.
- requests/httpx — интеграции с API.
- pydantic — валидация схем и моделей.
Работаем в вашем или нашем контуре. Подбираем стек под задачи, бюджет и SLA.
Почему Airflow
- Собираем данные из API и выгрузок. Ретраи, бэкофф, квоты/скорость, идемпотентность.
- Очищаем: удаляем дубли, приводим даты/валюты/часовые пояса.
- Сопоставляем идентификаторы SKU/GTIN/Артикул/1С. Ведём таблицы соответствий.
- Историзируем атрибуты (SCD). Храним первичные ключи и валидируем связи.
- Контроль качества: схемы, обязательные поля, диапазоны, аномалии.
- Публикуем витрины. Алерты в Telegram/почту при сбоях и задержках.
На скриншоте: DAG в Airflow — сбор, очистка, загрузка, публикация.
50–100 API
Подключаем десятки API. Сначала сохраняем «сырые» данные (Staging) без изменений — это страховка и аудит. Затем строим модель: факты и измерения. Отдельно решаем, что хранить в ClickHouse, а что — в PostgreSQL.
- Факты: продажи, транзакции, показы/клики — большие таблицы, апенды.
- Измерения: товары, категории, магазины, прайс‑листы — атрибуты, SCD.
Слой за слоем: сырые данные, очистка, модель, витрины. Для больших таблиц — инкрементальная загрузка, для чувствительных — CDC.
Витрины и представления
Делаем слой представлений (views) и материализованных витрин под конкретные вопросы. Это ускоряет отчёты и упрощает SQL. Правила агрегации — как код, под ревью.
- Views — для онлайна и гибкости.
- Materialized views — для тяжёлой аналитики.
- Инкрементальные витрины — для больших фактов.
Админ‑панель
Предоставляем удобный интерфейс: веб‑приложение (Next.js), телеграм‑бот или Streamlit. Запуск задач, просмотр статусов, ручные перезапуски, выгрузки, роль‑доступ.
Интерфейс под вашу команду: минимум кликов — максимум результата.
Git/S3/CI
Код храним в GitLab/GitHub. Для файлов используем S3 (обычно MinIO — бесплатный и удобный). Логика сборки — в Docker. Деплой — через CI/CD. MinIO используем для хранения изображений (иконки, артефакты), выгрузок и бэкапов.
- Git — ветки, MR, ревью, релизы.
- MinIO/S3 — бэкапы выгрузок, снимки данных, отчётные артефакты и изображения.
- CI/CD — проверка кода, тесты ETL, автодеплой.
Инфраструктура
Разворачиваем в Kubernetes или на виртуалках — по вашему выбору. Секреты в менеджере секретов, доступ по ролям, сетевые политики, аудит.
- Kubernetes — масштабирование воркеров ETL, горизонтальные автоскейлеры.
- Airflow — центральная оркестрация DAG, SLA, ретраи, идемпотентность.
- Ваша VPC/облако — секреты в менеджере (Vault/YC Lockbox), политики сети.
ML и ИИ
Когда данные собраны и приведены к модели, подключаем алгоритмы. Цель — принимать решения быстрее и точнее: прогнозировать, рекомендовать, оптимизировать.
- Прогноз спроса (учёт сезонности, промо, конкурентов), динамические цены.
- Оптимизация закупок и логистики: дни до нуля, оборачиваемость.
- Оптимизация рекламы: ставки, бюджет, ROMI; связь с остатками/ценой.
- LLM/VLM: анализ отзывов, поиск по описаниям, сравнение карточек.
Админ-панель и управление
Предоставляем удобный интерфейс: веб-приложение (Next.js), телеграм-бот или Streamlit. Запуск задач, просмотр статусов, ручные перезапуски, выгрузки, роль-доступ.
Интерфейс под вашу команду: минимум кликов — максимум результата.
Результаты
- Видите полную картину по всем площадкам в одном месте.
- Управляете ценами осознанно. Снижаете неликвид.
- Планируете закупки по прогнозу спроса.
- Оптимизируете рекламу на данных, а не на ощущениях.
Этапы внедрения
- Аудит данных и целей. Согласуем метрики.
- Проектирование архитектуры. Источники и витрины.
- Настройка сборки: Airflow, коннекторы, расписания.
- Моделирование DWH. Витрины под отчёты и решения.
- Отчёты в DataLens. Экспорты в Excel через XlsxWriter.
- ML‑модули: прогноз, цены, закупки.
- Обучение команды. Регламенты и поддержка.
4 стадии работы с данными
- Бизнес‑кейсы. Формулируем вопросы и решения. Что важно собирать: продажи, остатки, цены, конкуренты, возвраты, логистика.
- Сбор и качество. Источники (API/выгрузки/1С), SLA и контроль качества, идентификаторы, дедупликации.
- Модель и витрины. Факты/измерения, инкрементальность, представления под пользователей.
- Принятие решений. Дашборды/Excel, алерты, A/B‑гипотезы, регламенты.
Примеры: 12Storeez — пользователи смотрели на сайте, но покупали у реселлеров (Lamoda) дешевле; появилось решение по ценам/ассортименту.
Hoff — пропущено ~1% адресов; это были высотки, давшие ~3% возвратов. Исправили справочники и подтянули качество адресации.
Опыт
Делали проекты с пайплайнами в Airflow, витринами в ClickHouse и отчётами в DataLens. Интегрировали данные 1С, маркетплейсов и агрегаторов. Под каждую компанию адаптировали модель и отчётность. Обобщаем опыт, не раскрывая детали.
Качество данных и идентификация
У разных площадок разные идентификаторы. Мы выстраиваем сопоставление: SKU, артикул, баркод, внутренний код, 1C. Разрешаем дубли и «разъехавшиеся» карточки.
- Профили качества: обязательные поля, диапазоны, форматы, ссылочная целостность.
- Идентификация и мэппинг: ключи соответствий, таблицы соответствий, аудит.
- Дедупликация: правила сравнения, подтверждение вручную при необходимости.
- Контроль изменений: кто и когда поменял атрибуты, отчёт о расхождениях.
Сопоставление идентификаторов снижает ошибки в отчётах и прогнозах.
Производительность и масштабирование
ClickHouse — для быстрых аналитических запросов; PostgreSQL — для справочников и интеграций. Дизайн таблиц и индексов под ваши отчёты.
- ClickHouse: партиции по дате/категории, сортировка по ключам, агрегирующие таблицы, материализованные представления.
- PostgreSQL: индексы, партиционирование, autovacuum-параметры, внешние ключи.
- Инкрементальные загрузки: только изменения, CDC, upsert‑паттерны.
- Кэширование: Redis для горячих агрегатов и UI-ответов.
Витрины и отчёты
Делаем отчёты для ежедневной работы руководителя, категорийщика, закупщика и маркетолога. Всё — в несколько кликов. Сравнение с конкурентами (MPStats) — отдельные витрины для долей, цен и динамики.
Ежедневный отчёт: продажи, остатки, оборачиваемость, дни до нуля.
Финансы: выручка, комиссии, удержания, сверка выплат.
Реклама: ставки, CPC, CTR, ROMI. Связь с продажами и остатками.
Карта складов и FBS/FBO по России
WB/Ozon FBO и FBS точки (пример данных). Для реального кейса подключаемся к вашим справочникам.
Москва: ПВЗ и распределение покупателей
Размер маркера — количество покупателей (пример). Можно сегментировать по товарам/категориям.
Роли и процесс работы
Вы будете понимать, кто и что делает каждый день. Решения принимаются быстро и прозрачно.
- Руководитель: видит «картину дня», принимает решения по ценам и бюджету.
- Категорийщик: контролирует ассортимент, остатки, оборачиваемость.
- Маркетолог: ведёт кампании на базе метрик и ограничений по складу.
- Аналитик: проектирует витрины, проверяет качество, автоматизирует выгрузки.
Резервирование и DR
Делаем бэкапы и план восстановления. Тестируем сценарии отказа.
- Бэкап баз и конфигураций (S3/MinIO) с retention.
- Репликация ClickHouse/PG при необходимости.
- План восстановления и регламенты ответственных.
Машинное обучение и ИИ
Когда данные собраны и приведены к модели, подключаем алгоритмы. Цель — принимать решения быстрее и точнее: прогнозировать, рекомендовать, оптимизировать.
- Прогноз спроса по SKU и категориям (сезонность, тренды, промо).
- Динамическое ценообразование с учётом конкурентов и остатков.
- Оптимизация закупок: когда и сколько заказывать.
- Оптимизация рекламы: ставки, распределение бюджета, ROMI.
- Анализ отзывов: тональность, темы, причины возвратов (LLM).
- Компьютерное зрение: проверка карточек, соответствие фото (OpenCV).
- VLM-модели: понимание изображения + текста, сравнение карточек.
- Рекомендации ассортимента и кросс-продаж.
Стек ML/AI: TensorFlow, OpenCV, LLM/VLM-модели. Храним эмбеддинги в ChromaDB при необходимости.
Развёртывание: bare-metal с GPU, on‑premise, или API провайдеров. По желанию — хостим у нас.
ML-пайплайн использует витрины как стабильный источник данных и пишет результаты обратно.
Процессы и SLA
- Расписания: ежедневно/почасово/по событию; окна задержек; приоритеты.
- Мониторинг: Airflow, логи, метрики (задержка, объёмы, ошибки).
- Качество: уникальность, полнота, схемы, пороги аномалий.
- Регламенты принятия решений и ответственные за витрины.
Мониторинг: задержка данных, провал задания, качество загрузок.
Результаты для бизнеса
- Видите полную картину по всем площадкам в одном месте.
- Управляете ценами осознанно. Снижаете неликвид.
- Планируете закупки по прогнозу спроса.
- Оптимизируете рекламу на данных, а не на ощущениях.
Роли и процесс
- Руководитель: видит «картину дня», принимает решения по ценам и бюджету.
- Категорийщик: контролирует ассортимент, остатки, оборачиваемость.
- Маркетолог: ведёт кампании на базе метрик и ограничений по складу.
- Аналитик: проектирует витрины, проверяет качество, автоматизирует выгрузки.
Политика хранения
Мы не полагаемся на долгосрочное хранение у маркетплейсов: там история ограничена. Храним у вас столько, сколько нужно бизнесу: от 2 лет до «бессрочно» — по политике компании и требованиям комплаенса. MinIO используем для сохранения изображений и отчётных артефактов.
- Staging (raw) — полный слепок ответов API.
- ODS/DWH — нормализованные таблицы с историзацией.
- S3/MinIO — архивы, бэкапы, большие бинарные файлы.
Безопасность и доступы
- Храним доступы в секретах, разделяем роли.
- Разграничиваем доступ к витринам по отделам.
- Логируем действия и операции загрузки.
FAQ
Сколько это занимает по времени?
Пилот — 1–2 месяца. Полный контур — от 3–6 месяцев, зависит от источников и требований.
Можно ли начать с малого?
Да. Стартуем с ключевых витрин: продажи и остатки. Дальше наращиваем финансы, рекламу, конкурентов.
Нужен ли MPStats?
Не обязателен, но ускоряет конкурентный анализ. Мы учитываем и внутренние данные площадок.
Глоссарий
- DWH — хранилище данных для аналитики.
- SCD — историзация изменений справочных атрибутов.
- Витрина — агрегированная таблица для отчётов.
- ETL/ELT — сбор, преобразование, загрузка данных.
Стоимость и сроки
Пилот — 1–2 месяца. Полноценное внедрение — от 3–6 месяцев. Бюджет зависит от количества источников, объёма данных и требований к SLA.